大家可能曾经或多或少有过这样的困扰:在某些网页/Wiki上面,好不容易找到我们期望的信息以后,点进去发现404了,就会很影响使用者的体验。 而对于我们自己的页面来说,我们当然不想让我们自己的用户有这样的体验啦。
AWS 提供的解决方案
基于这样的一种痛点,AWS提供了一个解决方案:基于CloudWatch Synthetics 的Broken Link check。
我们可以基于我们的需求使用CloudWatch Synthetics创建一个 做Broken link check 的Canary。
更多关于如何使用CloudWatch Synthetics 创建Canary,请移步官方文档
,我们这篇文章将更多的聚焦在我们修改过后的版本以及我们提供的一键部署的实现。
AWS 的实现所存在的问题
AWS 已经提供了一个版本的实现,但是AWS 的实现并不能完全满足我们的要求:它通过爬取页面上的超链接,然后一层一层的爬取与扫描,而不在乎它当前扫描的页面到底还是不是我们期望它扫描的页面(停止条件是根据用户设置的一个depth 参数来判断到底需要扫描多少链接)。这种实现下,我们即使将这个depth 设置的再大也不能保证我们自己的页面会被完全扫描到。 这样的话,既费钱,也没有满足我们的需求。
改进后的版本
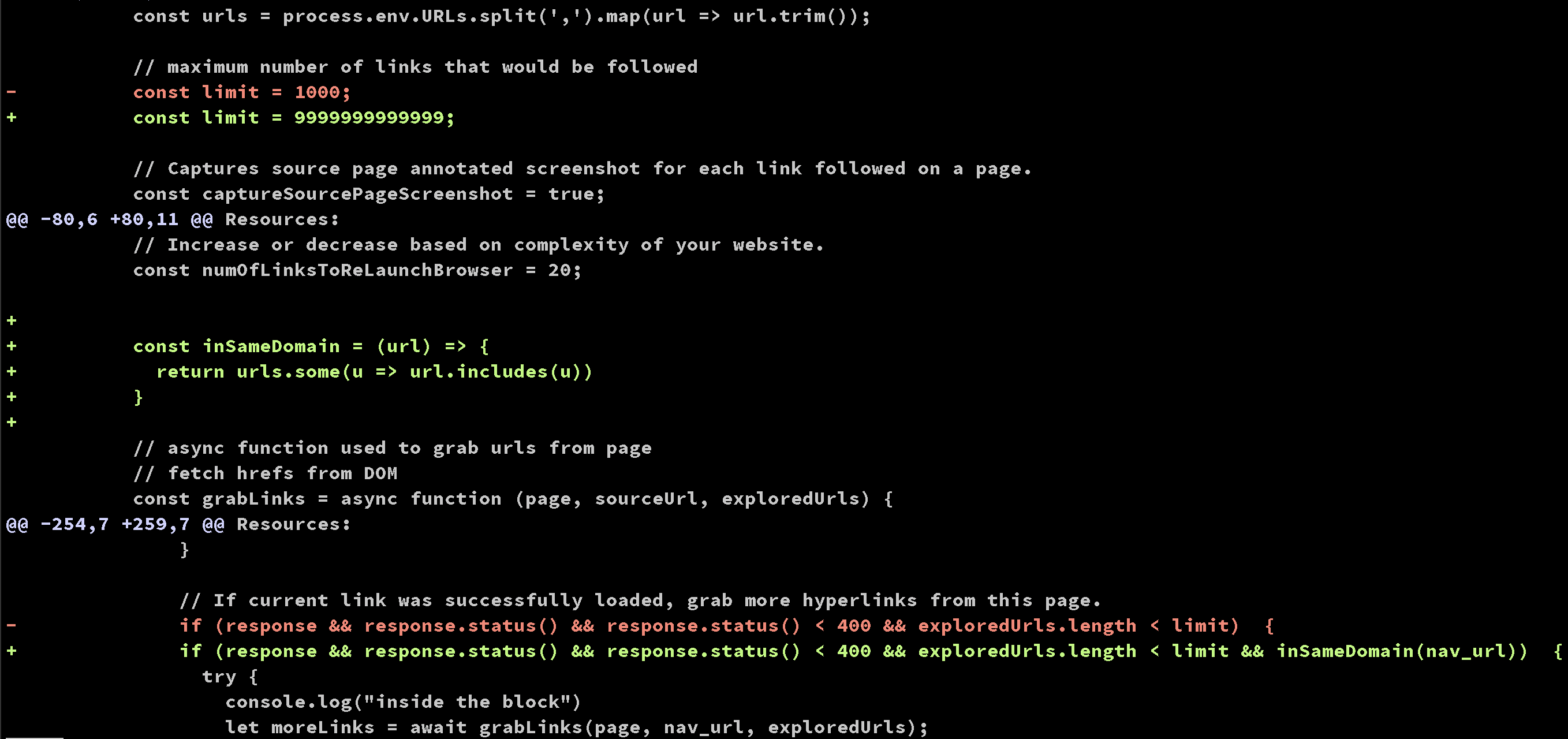
基于AWS 的实现,我在上面做了些许修改,让Broken Link Checker 能真正扫描所有在我们页面上引用的链接,不管是外部还是内部,但又不会深入非我们期望扫描的页面去扫描。 实现在这里 ,使用方式请移步Readme ,有需要自取。
改进方式其实也很简单:在进一步扫描页面的子链接之前,先判断当前页面是不是和我们期望扫描的URL 在同一个domain 底下,只有在同一个domain 才继续深入爬取链接。
这样我们就可以将Depth 设置得足够大,Canary 会在扫描完所有需要扫描的链接以及页面以后停下来。
适用场景
Broken link checker 有自身特有的适用性,并不适合所有网页应用。
不适用
- 它不适合动态网页应用的扫描,
- 它不适用需要身份认证的页面的扫描 像以上场景的扫描应该被冒烟测试或者端到端(E2E)测试所覆盖,而不是简单的链接扫描。
适用于
- 文档/Wiki 等静态页面。 个人认为文档和Wiki 的使用场景是最需要它也是最能让它发挥作用的地方。